IBM MQ Gateways in Geographically Distributed Installations
In its simplest form, an IBM MQ architecture would involve a server and many clients connecting to it and sending requests or waiting for replies. This is a cartoonish simplification of what reality usually looks like, but it is entirely sufficient for what we need here.
There are many ways for such an architecture to grow and change, and some of these ways can put considerable strain on it. One thing that happens often is that the server is migrated in the cloud. Another one is that clients grow geographically.
IBM MQ is a superbly stable environment. In all likelihood it would keep working in these two cases. But performance may degrade. Let’s consider what’s happening using some (not so) fictional scenarios.
You may have a system, say Internet Banking, that uses your Core Banking to get what it needs to then show to its users. The Internet Banking systems uses MQ Client libraries to connect to the Core Banking Queue Manager and send requests. It’s been working fine for years.
FIXME: We need a picture of the two boxes with no cloud in between…
So your Internet Banking is a multi-threaded application. Or it may be an event driven asynchronous application. Either way it generates many requests waiting for their replies. And before this used to work very well.
If we delve into details, sending every message has its overhead. When client and server are “close” in the network this overhead is very little in terms of time spent. However, if we stretch the network distance between a client and a server what we begin to see is that the latency of network starts to increase. Even if the link has a large bandwidth, latency increases almost inevitably when the two endpoints are stretched apart. And latency (and not bandwidth) is what affects the overhead most.
So now that those two endpoints are stretched (however little), your Internet Banking system incurs considerable delay for every message it sends. In the end, end users would suffer the degraded performance.
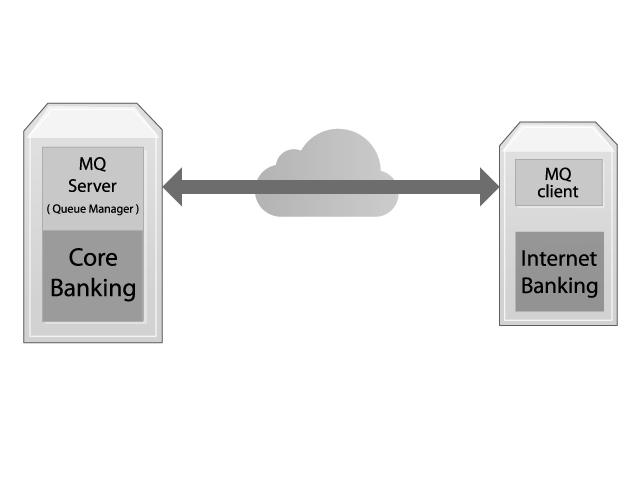
If you have more geographically distributed locations the problem only gets worse.
At a first glance introducing another QueueManager doesn’t help. That latency is still not reduced. Very technically speaking, it has probably increased slightly. However what was reduced is the latency between the client and the Queue Manager it connects to.
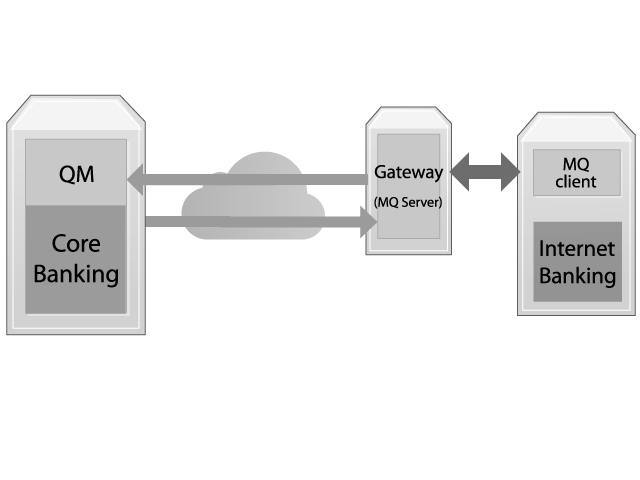
Now the latency is between the two Queue Managers. And Queue Managers can batch messages together and they are very smart about how they do it. In peak hours, when hundreds of messages are coming in per second, Queue Managers would pack several of them together. As a result, the overhead for 20 or 30 messages will be reduced to the equivalent of sending one. The trick here is that the overhead price is paid by batch, not by message. MQ Client libraries, on the other hand, cannot batch messages. So the overhead price is paid by the messages. We are still paying this price but by introducing a new Queue Manager it is way lower.
There are many parameters that affect the way Queue Managers batch messages. A selection would inlude BATCHSZ, BATCHLIM, and BATCHINT. Even with default configuration in real, production installations, performance improvements are considerable. Fine tuning these parameters yields even better results for your systems.
XQuadro has designed, built, deployed, and tuned similar solutions so many times that we have a special name for the Queue Manager we introduced above: MQ Gateway.